
OpenJDK 源码阅读之 Java 输入输出(I/O) 之 字节流输入
标签(空格分隔): 源代码阅读 Java 封神之路
Java 的输入输出总是给人一种很混乱的感觉,要想把这个问题搞清楚,必须对各种与输入输出相关的类之间的关系有所了解。只有你了解了他们之间的关系,知道设计这个类的目的是什么,才能更从容的使用他们。
我们先对 Java I/O 的总体结构进行一个总结,再通过分析源代码,给出把每个类的关键功能是如何实现的。
Java I/O 的主要结构
Java 的输入输出,主要分为以下几个部分:
- 字节流
- 字符流
- Socket
- 新 I/O
每个部分,都包含了输入和输出两部分。
实现概要
这里只给出每个类的实现概要,具体每个类的实现分析,可以参见我的 GitHub-SourceLearning-OpenJDK 页面。根据导航中的链接,进入 java.io ,即可看到对每个类的分析。
字节流输入
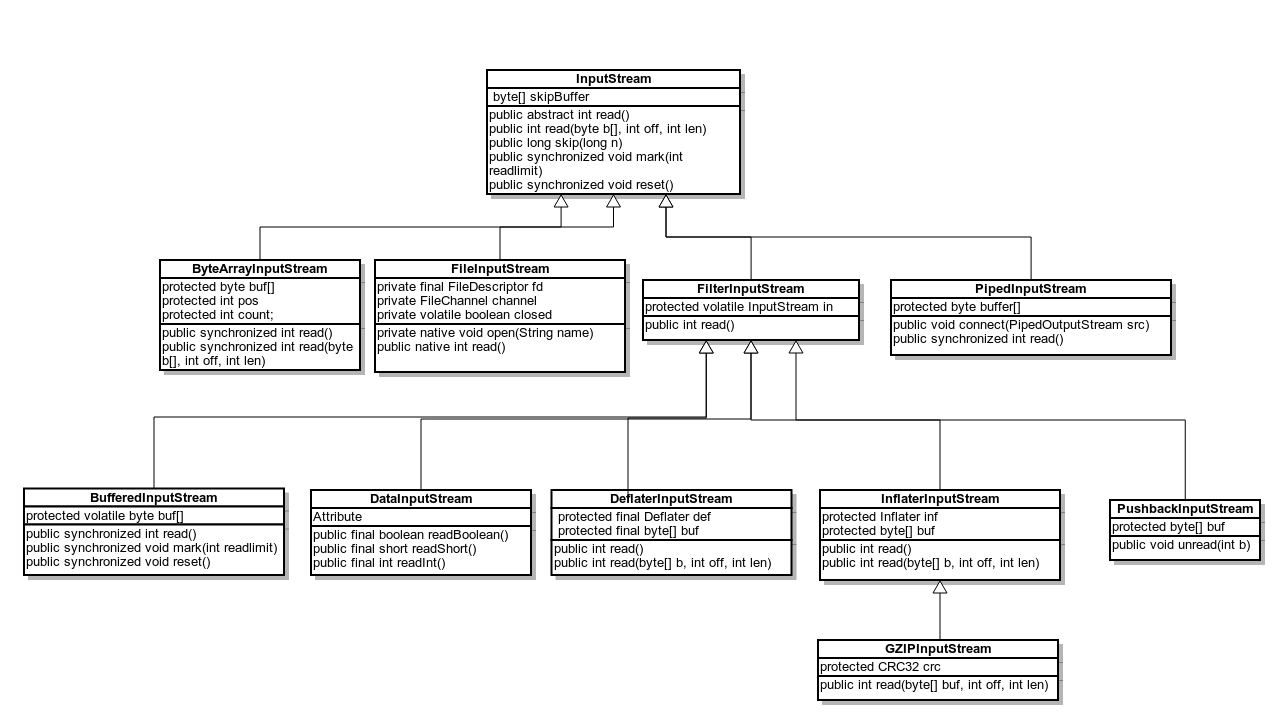
图1 Java 字节输入类
- InputStream
InputStream 是所有字节输入类的基类,它有一个未实现的 read 方法,子类需要实现这个 read 方法, 它和数据的来源相关。它的各种不同子类,或者是添加了功能,或者指明了不同的数据来源。
public abstract int read() throws IOException;
- ByteArrayInputStream
ByteArrayInputStream 有一个内部 buffer , 包含从流中读取的字节,还有一个内部 counter, 跟踪下一个要读入的字节。
protected byte buf[];
protected int pos;
这个类在初始化时,需要指定一个 byte[],作为数据的来源,它的 read,就读入这个 byte[] 中所包含的数据。
public ByteArrayInputStream(byte buf[]) {
this.buf = buf;
this.pos = 0;
this.count = buf.length;
}
public synchronized int read() {
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
- FileInputStream
FileInputStream 的数据来源是文件,即从文件中读取字节。初始化时,需要指定一个文件:
public FileInputStream(File file)
throws FileNotFoundException {
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkRead(name);
}
if (name == null) {
throw new NullPointerException();
}
fd = new FileDescriptor();
fd.incrementAndGetUseCount();
open(name);
}
以后读取的数据,都来自于这个文件。这里的 read 方法是一个 native 方法,它的实现与操作系统相关。
public native int read() throws IOException;
- FilterInputStream
FilterInputStream将其它输入流作为数据来源,其子类可以在它的基础上,对数据流添加新的功能。我们经常看到流之间的嵌套,以添加新的功能。就是在这个类的基础上实现的。所以,它的初始化中,会指定一个字节输入流:
protected volatile InputStream in;
protected FilterInputStream(InputStream in) {
this.in = in;
}
读取操作,就依靠这个流实现:
public int read() throws IOException {
return in.read();
}
- BufferedInputStream
BufferedInputStream 是 FilterInputStream 的子类,所以,需要给它提供一个底层的流,用于读取,而它本身,则为此底层流增加功能,即缓冲功能。以减少读取操作的开销,提升效率。
protected volatile byte buf[];
内部缓冲区由一个 volatile byte 数组实现,大多线程环境下,一个线程向 volatile 数据类型中写入的数据,会立即被其它线程看到。
read 操作会先看一下缓冲区里的数据是否已经全部被读取了,如果是,就调用底层流,填充缓冲区,再从缓冲区中按要求读取指定的字节。
public synchronized int read() throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return getBufIfOpen()[pos++] & 0xff;
}
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf;
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
- DataInputStream
DataInputStream 也是 FilterInputStream 的子类,它提供的功能是:可以从底层的流中读取基本数据类型,例如 int, char 等等。DataInputStream 是非线程安全的, 你必须自己保证处理线程安全相关的细节。
例如,readBoolean 会读入一个字节,然后根据是否为0,返回 true/false。
public final boolean readBoolean() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (ch != 0);
}
readShort 会读入两个字节,然后拼接成一个 short 类型的数据。
public final short readShort() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (short)((ch1 << 8) + (ch2 << 0));
}
int 和 long 依此类推,分别读入4个字节,8个字节,然后进行拼接。
但是,浮点数就不能通过简单的拼接来解决了,而要读入足够的字节数,然后再按照 IEEE 754 的标准进行解释:
public final float readFloat() throws IOException {
return Float.intBitsToFloat(readInt());
}
- PushbackInputstream
PushbackInputstream 类也是FilterInputStream的子类,它提供的功能是,可以将已经读入的字节,再放回输入流中,下次读取时,可以读取到这个放回的字节。这在某些情境下是非常有用的。它的实现,就是依靠类似缓冲区的原理。被放回的字节,实际上是放在缓冲区里,读取时,先查看缓冲区里有没有字节,如果有就从这里读取,如果没有,就从底层流里读取。
缓冲区是一个字节数组:
protected byte[] buf;
读取时,优先从这里读取,读不到,再从底层流读取。
public int read() throws IOException {
ensureOpen();
if (pos < buf.length) {
return buf[pos++] & 0xff;
}
return super.read();
}
- PipedInputStream
PipedInputStream 与 PipedOutputStream 配合使用,它们通过 connect 函数相关联。
public void connect(PipedOutputStream src) throws IOException {
src.connect(this);
}
它们共用一个缓冲区,一个从中读取,一个从中写入。
PipedInputStream内部有一个缓冲区,
protected byte buffer[];
读取时,就从这里读:
public synchronized int read() throws IOException {
if (!connected) {
throw new IOException("Pipe not connected");
} else if (closedByReader) {
throw new IOException("Pipe closed");
} else if (writeSide != null && !writeSide.isAlive()
&& !closedByWriter && (in < 0)) {
throw new IOException("Write end dead");
}
readSide = Thread.currentThread();
int trials = 2;
while (in < 0) {
if (closedByWriter) {
/* closed by writer, return EOF */
return -1;
}
if ((writeSide != null) && (!writeSide.isAlive()) && (--trials < 0)) {
throw new IOException("Pipe broken");
}
/* might be a writer waiting */
notifyAll();
try {
wait(1000);
} catch (InterruptedException ex) {
throw new java.io.InterruptedIOException();
}
}
int ret = buffer[out++] & 0xFF;
if (out >= buffer.length) {
out = 0;
}
if (in == out) {
/* now empty */
in = -1;
}
return ret;
}
过程比我们想的要复杂,因为这涉及两个线程,需要相互配合,所以,需要检查很多东西,才能最终从缓冲区中读到数据。
PipedOutputStream 类写入时,会调用 PipedInputStream 的receive功能,把数据写入 PipedInputStream 的缓冲区。
我们看一下 PipedOutputStream.write 函数:
public void write(int b) throws IOException {
if (sink == null) {
throw new IOException("Pipe not connected");
}
sink.receive(b);
}
可以看出,调用了相关联的管道输入流的 receive 函数。
protected synchronized void receive(int b) throws IOException {
checkStateForReceive();
writeSide = Thread.currentThread();
if (in == out)
awaitSpace();
if (in < 0) {
in = 0;
out = 0;
}
buffer[in++] = (byte)(b & 0xFF);
if (in >= buffer.length) {
in = 0;
}
}
receive 的主要功能,就是把写入的数据放入缓冲区内。
注意注意的是,这两个类相互关联的对象,应该属于两个不同的线程,否则,容易造成死锁。